Как поисковики сканируют страницу Robots.txt для Яндекса и Google Как составить robots.txt правильно Инструменты для составления и проверки robots.txt Как поисковики сканируют страницу Роботы-краулеры Яндекса и Google посещают страницы сайта, оценивают содержимое, добавляют новые ресурсы и информацию о страницах в индексную базу поисковика.
Зачем нужно сканирование:
- Собрать данные для построения индекса — информацию о новых страницах и обновлениях на старых.
- Сравнить URL в индексе и в списке для сканирования.
- Убрать из очереди дублирующиеся URL, чтобы не скачивать их дважды.
Боты смотрят не все страницы сайта. Количество ограничено краулинговым бюджетом, который складывается из количества URL, которое может просканировать бот-краулер. Бюджета на объемный сайт может не хватить. Есть риск, что краулинговый бюджет уйдет на сканирование неважных или «мусорных» страниц, а чтобы такого не произошло, веб-мастеры направляют краулеров с помощью файла robots.txt.
Боты переходят на сайт и находят в корневом каталоге файл robots.txt, анализируют доступ к страницам и переходят к карте сайта — Sitemap, чтобы сократить время сканирования, не обращаясь к закрытым ссылкам. После изучения файла боты идут на главную страницу и оттуда переходят в глубину сайта.
Какие страницы краулер просканирует быстрее:
- Находятся ближе к главной.
Чем меньше кликов с главной ведет до страницы, тем она важнее и тем вероятнее ее посетит краулер. Количество переходов от главной до текущей страницы называется Click Distance from Index (DFI). - Имеют много ссылок.
Если многие ссылаются на страницу, значит она полезная и имеет хорошую репутацию. Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается. - Быстро загружаются.
Проверьте скорость загрузки инструментом, если она медленная — оптимизируйте код верхней части и уменьшите вес страницы.
Все посещения ботов-краулеров не фиксируют такие инструменты, как Google Analytics, но поведение ботов можно отследить в лог-файлах. Некоторые SEO-проблемы крупных сайтов можно решить с помощью анализа лог-файлов который также поможет увидеть проблемы со ссылками и распределение краулингового бюджета.
Посмотреть на сайт глазами поискового бота
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt. Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется "robots.txt", название написано только строчными буквами, "Robots.TXT" и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: "сайт.рф" — "xn--80aswg.xn--p1ai".
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами — http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву "disallow". Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег "noindex" или "none".
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — "noindex" или атрибута "rel" со значением "nofollow".
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или "nofollow" , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена "/robots.txt".
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру "noflashhtml" и "backhtml". Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте "noindex".
Как составить robots.txt правильно
Файл можно составить в любом текстовом редакторе и сохранить в формате txt. В нем нужно прописать инструкцию для роботов: указание, каким роботам реагировать, и разрешение или запрет на сканирование файлов.
Инструкции отделяют друг от друга переносом строки.
Символы robots.txt
"*" — означает любую последовательность символов в файле.
"$" — ограничивает действия "*", представляет конец строки.
"/" — показывает, что закрывают для сканирования.
"/catalog/" — закрывают раздел каталога;
"/catalog" — закрывают все ссылки, которые начинаются с "/catalog".
"#" — используют для комментариев, боты игнорируют текст с этим символом.
User-agent: * Disallow: /catalog/ #запрещаем сканировать каталог
Директивы robots.txt
Директивы, которые распознают все краулеры:
User-agent
На первой строчке прописывают правило User-agent — указание того, какой робот должен реагировать на рекомендации. Если запрещающего правила нет, считается, что доступ к файлам открыт.
Для разного типа контента поисковики используют разных ботов:
- Google: основной поисковый бот называется Googlebot, есть Googlebot News для новостей, отдельно Googlebot Images, Googlebot Video и другие;
- Яндекс: основной бот называется YandexBot, есть YandexDirect для РСЯ, YandexImages, YandexCalendar, YandexNews, YandexMedia для мультимедиа, YandexMarket для Яндекс.Маркета и другие.
Для отдельных ботов можно указать свою директиву, если есть необходимость в рекомендациях по типу контента.
User-agent: * — правило для всех поисковых роботов;
User-agent: Googlebot — только для основного поискового бота Google;
User-agent: YandexBot — только для основного бота Яндекса;
User-agent: Yandex — для всех ботов Яндекса. Если любой из ботов Яндекса обнаружит эту строку, то другие правила User-agent: * учитывать не будет.
Sitemap
Указывает ссылку на карту сайта — файл со структурой сайта, в котором перечислены страницы для индексации:
User-agent: * Sitemap: http://site.com/sitemap.xml
Некоторые веб-мастеры не делают карты сайтов, это не обязательное требование, но лучше составить Sitemap — этот файл краулеры воспринимают как структуру страниц, которые не можно, а нужно индексировать.
Disallow
Правило показывает, какую информацию ботам сканировать не нужно.
Если вы еще работаете над сайтом и не хотите, чтобы он появился в незавершенном виде, можно закрыть от сканирования весь сайт:
User-agent: * Disallow: /
После окончания работы над сайтом не забудьте снять блокировку.
Разрешить всем ботам сканировать весь сайт:
User-agent: * Disallow:
Для этой цели можно оставить robots.txt пустым.
Чтобы запретить одному боту сканировать, нужно только прописать запрет с упоминанием конкретного бота. Для остальных разрешение не нужно, оно идет по умолчанию:
Пользователь-агент: BadBot Disallow: /
Чтобы разрешить одному боту сканировать сайт, нужно прописать разрешение для одного и запрет для остальных:
User-agent: Googlebot Disallow: User-agent: * Disallow: /
Запретить ботам сканировать страницу:
User-agent: * Disallow: /page.html
Запретить сканировать конкретную папку с файлами:
User-agent: * Disallow: /name/
Запретить сканировать все файлы, которые заканчиваются на ".pdf":
User-agent: * Disallow: /*.pdf$
Запретить сканировать раздел http://site.com/about/:
User-agent: * Disallow: /about/
Запись формата "Disallow: /about" без закрывающего "/" запретит доступ и к разделу http://site.com/about/, к файлу http://site.com/about.php и к другим ссылкам, которые начинаются с "/about".
Если нужно запретить доступ к нескольким разделам или папкам, для каждого нужна отдельная строка с Disallow:
User-agent: * Disallow: /about Disallow: /info Disallow: /album1
Allow
Disallow-наоборот — директива, разрешающая сканирование. Для роботов действует правило: что не запрещено, то разрешено, но иногда нужно разрешить доступ к какому-то файлу и закрыть остальную информацию.
Разрешено сканировать все, что начинается с "/catalog", а все остальное запрещено:
User-agent: * Allow: /catalog Disallow: /
Сканировать файл "photo.html" разрешено, а всю остальную информацию в каталоге /album1/ запрещено:
User-agent: * Allow: /album1/photo.html Disallow: /album1/
Заблокировать доступ к каталогам "site.com/catalog1/" и "site.com/catalog2/" но разрешить к "catalog2/subcatalog1/":
User-agent: * Disallow: /catalog1/ Disallow: /catalog2/ Allow: /catalog2/subcatalog1/
Бывает, что для страницы оказываются справедливыми несколько правил. Тогда робот будет отсортирует список от меньшего к большему по длине префикса URL и будет следовать последнему правилу в списке.
Директивы, которые распознают боты Яндекса:
Clean-param
Некоторые страницы дублируются с разными GET-параметрами или UTM-метками, которые не влияют на содержимое. К примеру, если в каталоге товаров использовали сортировку или разные id.
Чтобы отследить, с какого ресурса делали запрос страницы с книгой book_id=123, используют ref:
"www.site. com/some_dir/get_book.pl?ref=site_1& book_id=123"
"www.site. com/some_dir/get_book.pl?ref=site_2& book_id=123"
"www.site. com/some_dir/get_book.pl?ref=site_3& book_id=123"
Страница с книгой одна и та же, содержимое не меняется. Чтобы бот не сканировал все варианты таких страниц с разными параметрами, используют правило Clean-param:
User-agent: Yandex Disallow: Clean-param: ref /some_dir/get_book.pl
Робот Яндекса сведет все адреса страницы к одному виду:
"www.example. com/some_dir/get_book.pl? book_id=123"
Для адресов вида:
"www.example2. com/index.php? page=1&sid=2564126ebdec301c607e5df"
"www.example2. com/index.php? page=1&sid=974017dcd170d6c4a5d76ae"
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: sid /index.php
Для адресов вида
"www.example1. com/forum/showthread.php? s=681498b9648949605&t=8243"
"www.example1. com/forum/showthread.php? s=1e71c4427317a117a&t=8243"
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s /forum/showthread.php
Если переходных параметров несколько:
"www.example1. com/forum_old/showthread.php? s=681498605&t=8243&ref=1311"
"www.example1. com/forum_new/showthread.php? s=1e71c417a&t=8243&ref=9896"
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s&ref /forum*/showthread.php
Host
Правило показывает, какое зеркало учитывать при индексации. URL нужно писать без "http://" и без закрывающего слэша "/". Директиву распознают только боты Яндекса.
User-agent: Yandex Disallow: /about Host: www.site.com
Crawl-delay
Частая загрузка страниц может нагружать сервер, поэтому устанавливают Crawl-delay — время ожидания робота в секундах между загрузками. Мощным серверам не требуется.
Время ожидания — 4 секунды:
User-agent: * Allow: /album1 Disallow: / Crawl-delay: 4
Только латиница
Напомним, что все кириллические ссылки нужно перевести в Punycode с помощью любого конвертера.
Неправильно:
User-agent: Yandex Disallow: /каталог
Правильно:
User-agent: Yandex Disallow: /xn--/-8sbam6aiv3a
Пример robots.txt
Запись означает, что правило справедливо для всех роботов: запрещено сканировать ссылки из корзины, из встроенного поиска и админки, карта сайта находится по ссылке http://site.com/sitemap, ref не меняет содержание страницы get_book:
User-agent: * Disallow: /bin/ Disallow: /search/ Disallow: /admin/ Sitemap: http://site.com/sitemap Clean-param: ref /some_dir/get_book.pl
Инструменты для составления и проверки robots.txt
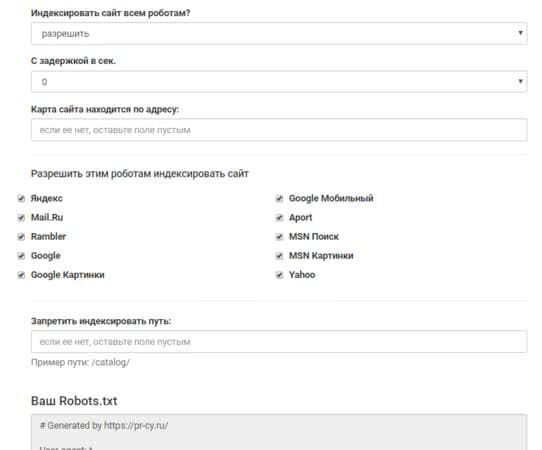
Составить robots.txt бесплатно поможет инструмент для генерации robots.txt от PR-CY, он позволит закрыть или открыть весь сайт для ботов, указать путь к карте сайта, настроить ограничение на посещение страниц, закрыть доступ некоторым роботам и установить задержку:
Графы инструмента для заполнения
Для проверки файла robots.txt на ошибки у поисковиков есть собственные инструменты:
Инструмент проверки файла robots.txt от Google позволит проверить, как бот видит конкретный URL. В поле нужно ввести проверяемый URL, а инструмент покажет, доступна ли ссылка.
Инструмент проверки от Яндекса покажет, правильно ли заполнен файл. Нужно указать сайт, для которого создан robots.txt, и перенести его содержимое в поле.
Файл robots.txt не подходит для блокировки доступа к приватным файлам, но направляет краулеров к карте сайта и дает рекомендации для быстрого сканирования важных материалов ресурса.